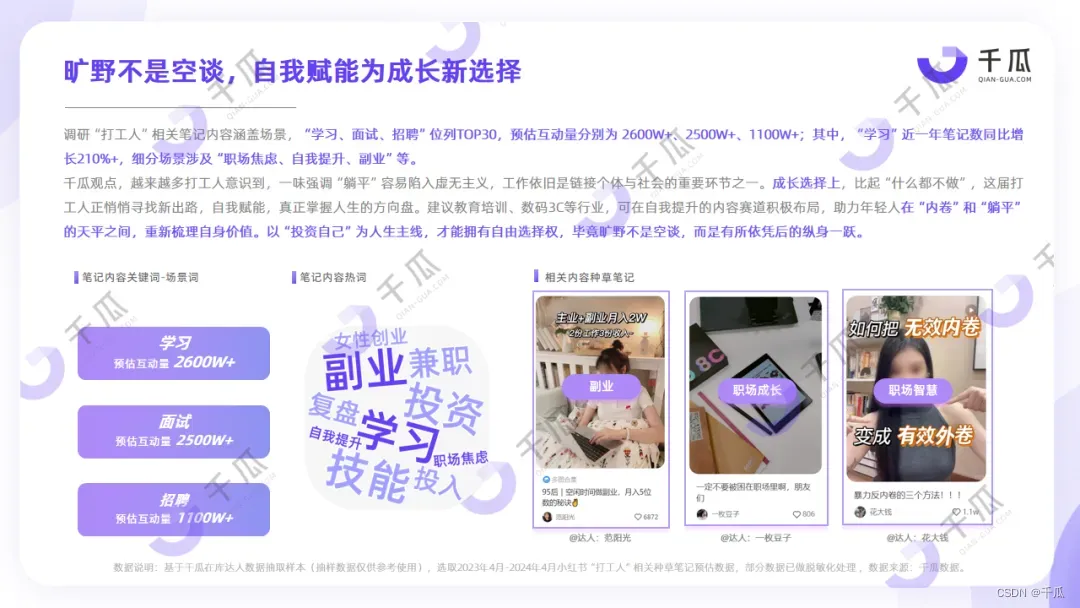
目录
一,二叉树需要实现的功能
二,下面是各功能详解
0.思想:
1.创建二叉树结点:
2.通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树
3.二叉树销毁:
4.前序遍历:
5.中序遍历:
6.后序遍历:
7.层序遍历:
1.先实现队列的基本功能:
2.基于队列实现层序:
8.计算各类结点数量:
1.计算二叉树结点数量:
2.计算叶子结点数量:
3.计算K层结点数量:
9.二叉树查找值为X的结点:
10.判断二叉树是否为完全二叉树:
一,二叉树需要实现的功能
// 通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树
BTNode* BinaryTreeCreate(BTDataType* a, int n, int* pi);
// 二叉树销毁
void BinaryTreeDestory(BTNode** root);
// 二叉树节点个数
int BinaryTreeSize(BTNode* root);
// 二叉树叶子节点个数
int BinaryTreeLeafSize(BTNode* root);
// 二叉树第k层节点个数
int BinaryTreeLevelKSize(BTNode* root, int k);
// 二叉树查找值为x的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x);
// 二叉树前序遍历
void BinaryTreePrevOrder(BTNode* root);
// 二叉树中序遍历
void BinaryTreeInOrder(BTNode* root);
// 二叉树后序遍历
void BinaryTreePostOrder(BTNode* root);
// 层序遍历
void BinaryTreeLevelOrder(BTNode* root);
// 判断二叉树是否是完全二叉树
int BinaryTreeComplete(BTNode* root);二,下面是各功能详解
0.思想:
下面很多功能都涉及分治的思想(分治法是算法常用的解题方法之一,是将一个大的问题拆分为若干小的问题。)
1.创建二叉树结点:
//重命名存储变量类型,方便更改
typedef char BTDataType;
typedef struct BinaryTreeNode
{
BTDataType _data;
struct BinaryTreeNode* _left;
struct BinaryTreeNode* _right;
}BTNode;2.通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树
// 通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树
BTNode* BinaryTreeCreate(BTDataType* a, int n, int* pi) {
if (*pi >= n || a[*pi] == '#') {
(*pi)++;
return NULL;
}
BTNode* Node = (BTNode*)malloc(sizeof(BTNode));
if (Node == NULL) {
perror("BinaryTreeCreate::malloc");
exit(0);
}
Node->_data = a[*pi];
(*pi)++;
Node->_left = BinaryTreeCreate(a, n, pi);
Node->_right = BinaryTreeCreate(a, n, pi);
return Node;
}按照以上所给数组描述,我们创建出的二叉树:

3.二叉树销毁:
二叉树的存储类似链表,可以由前面的结点找到后面的结点,因此二叉树的销毁也是由后向前销毁会方便很多,所以我们采取后序来销毁二叉树
// 二叉树销毁
void BinaryTreeDestory(BTNode** root) {
if (*root == NULL) {
return;
}
BinaryTreeDestory(&(*root)->_left);
BinaryTreeDestory(&(*root)->_right);
free(*root);
*root = NULL;
}4.前序遍历:
i、先访问根结点;
ii、再前序遍历左子树;
iii、最后前序遍历右子树;
算法实现:
// 二叉树前序遍历
void BinaryTreePrevOrder(BTNode* root) {
if (root != NULL) {
printf("%c ", root->_data);
BinaryTreePrevOrder(root->_left);
BinaryTreePrevOrder(root->_right);
}
}
5.中序遍历:
i、中序遍历左子树;
ii、访问根结点;
iii、中序遍历右子树
算法实现:
// 二叉树中序遍历
void BinaryTreeInOrder(BTNode* root) {
if (root != NULL) {
BinaryTreeInOrder(root->_left);
printf("%c ", root->_data);
BinaryTreeInOrder(root->_right);
}
}
6.后序遍历:
i、后序遍历左子树
ii、后序遍历右子树
iii、访问根结点
算法实现:
// 二叉树后序遍历
void BinaryTreePostOrder(BTNode* root) {
if (root != NULL) {
BinaryTreePostOrder(root->_left);
BinaryTreePostOrder(root->_right);
printf("%c ", root->_data);
}
}
7.层序遍历:
设二叉树的根节点所在层数为1,层序遍历就是从所在二叉树的根节点出发,首先访问第一层的树根节点,然后从左到右访问第2层上的节点,接着是第三层的节点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历。
思路:层序遍历需要用到队列的知识,就是先将根结点入队,判断队列是否为空,循环将队首元素出队的同时队首元素子节结点入队
算法实现:
1.先实现队列的基本功能:
typedef BTNode QDataType;
// 链式结构:表示队列
typedef struct QListNode
{
struct QListNode* _next;
QDataType* _data;
}QNode;
// 队列的结构
typedef struct Queue
{
QNode* _front;
QNode* _rear;
}Queue;
// 初始化队列
void QueueInit(Queue* q) {
assert(q);
q->_front = NULL;
q->_rear = NULL;
}
int QueueEmpty(Queue* q);
// 队尾入队列
void QueuePush(Queue* q, QDataType* data) {
assert(q);
QNode* tmp = (QNode*)malloc(sizeof(QNode));
if (tmp == NULL) {
perror("QueuePush:malloc");
return;
}
tmp->_data = data;
tmp->_next = NULL;
if (QueueEmpty(q)) {
q->_front = tmp;
q->_rear = tmp;
}
q->_rear->_next = tmp;
q->_rear = tmp;
}
// 队头出队列
void QueuePop(Queue* q) {
if (QueueEmpty(q)) {
printf("Pop: Queue is empty\n"); // 更清晰的错误信息
exit(0);
}
q->_front = q->_front->_next;
//free(tmp);
}
// 获取队列头部元素
QDataType* QueueFront(Queue* q) {
return q->_front->_data;
}
// 获取队列队尾元素
QDataType* QueueBack(Queue* q) {
return q->_rear->_data;
}
// 获取队列中有效元素个数
int QueueSize(Queue* q) {
QNode* cur = q->_front;
int size = 0;
while (cur) {
size++;
cur = cur->_next;
}
return size;
}
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
int QueueEmpty(Queue* q) {
assert(q);
if (q->_front == NULL) {
return 1;
}
return 0;
}
// 销毁队列
void QueueDestroy(Queue* q) {
assert(q);
while (!QueueEmpty(q)) {
QueuePop(q);
}
}2.基于队列实现层序:
// 层序遍历
void BinaryTreeLevelOrder(BTNode* root) {
Queue* queue = (Queue*)malloc(sizeof(Queue));
BTNode* front;
QueueInit(queue);
if (root) {
QueuePush(queue, root);
}
while (!QueueEmpty(queue)) {
front = QueueFront(queue);
if (front->_left)
{
QueuePush(queue, front->_left);
}
if (front->_right)
{
QueuePush(queue, front->_right);
}
printf("%c ",front->_data);
QueuePop(queue);
}
printf("\n");
QueueDestroy(queue);
}8.计算各类结点数量:
1.计算二叉树结点数量:
// 二叉树节点个数
int BinaryTreeSize(BTNode* root) {
if (root == NULL) {
return 0;
}
else {
return BinaryTreeSize(root->_left) + BinaryTreeSize(root->_right) + 1;
}
}2.计算叶子结点数量:
// 二叉树叶子节点个数
int BinaryTreeLeafSize(BTNode* root) {
if (root == NULL) {
return 0;
}
if (root->_left == NULL && root->_right == NULL) {
return 1;
}
else {
return BinaryTreeLeafSize(root->_left) + BinaryTreeLeafSize(root->_right);
}
}3.计算K层结点数量:
// 二叉树第k层节点个数
int BinaryTreeLevelKSize(BTNode* root, int k) {
if (root == NULL) {
return 0;
}
if (k == 1) {
return 1;
}
return BinaryTreeLevelKSize(root->_left, k - 1) + BinaryTreeLevelKSize(root->_right, k - 1);
}9.二叉树查找值为X的结点:
// 二叉树查找值为x的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x) {
if (root==NULL) {
return NULL;
}
if (root->_data == x) {
return root;
}
BTNode* r1 = BinaryTreeFind(root->_left, x);
if (r1 != NULL) {
return r1;
}
return BinaryTreeFind(root->_right, x);
}10.判断二叉树是否为完全二叉树:
根据完全二叉树的定义,具有n个结点的完全二叉树与满二叉树中编号从1~n的结点一一对应。
算法思想:采用层次遍历算法,将所有结点加入队列(包括空结点)。遇到空结点时,查看其后是否有非空结点。若有,则二叉树不是完全二叉树。
判断二叉树是否为完全二叉树是二叉树层序遍历的基本用途之一,也要借助队列来实现;
算法实现:
// 判断二叉树是否是完全二叉树
int BinaryTreeComplete(BTNode* root) {
Queue queue;
QueueInit(&queue);
if (root) {
QueuePush(&queue, root);
}
while (!QueueEmpty(&queue)) {
BTNode* front = QueueFront(&queue);
QueuePop(&queue);
if (front == NULL) {
break;
}
QueuePush(&queue, front->_left);
QueuePush(&queue, front->_right);
}
while (!QueueEmpty(&queue)) {
BTNode* front = QueueFront(&queue);
QueuePop(&queue);
if (front) {
QueueDestroy(&queue);
return 0;
}
}
QueueDestroy(&queue);
return 1;
}